随着科技的飞速发展,人工智能(AI)正以前所未有的深度和广度影响着社会生活的各个领域,语言与语言教学也不例外。为了深入探讨人工智能背景下语言与语言教学的最新进展,交流研究成果,北京市语言学会定于2024年12月8日举办“北京市语言学会第17届学术年会暨2024年学术前沿论坛”。本次年会将以“人工智能背景下的语言与语言教学研究”为主题,旨在汇聚语言学界、教育技术界及语言教学领域的专家学者,共同探索人工智能技术在语言教学与研究中的应用路径与未来趋势。诚邀相关领域专家学者、一线教师、科研人员莅临大会,交流数智时代语言研究的新趋势、新思想、新技术和新方法。
现将二号通知,公布如下:
一、会议主题
人工智能背景下的语言与语言教学研究
二、会议时间
2024年12月8日(星期日)上午,会期半天
报到时间:7:30—8:20
会议时间:8:30—12:00
离会时间:12:00
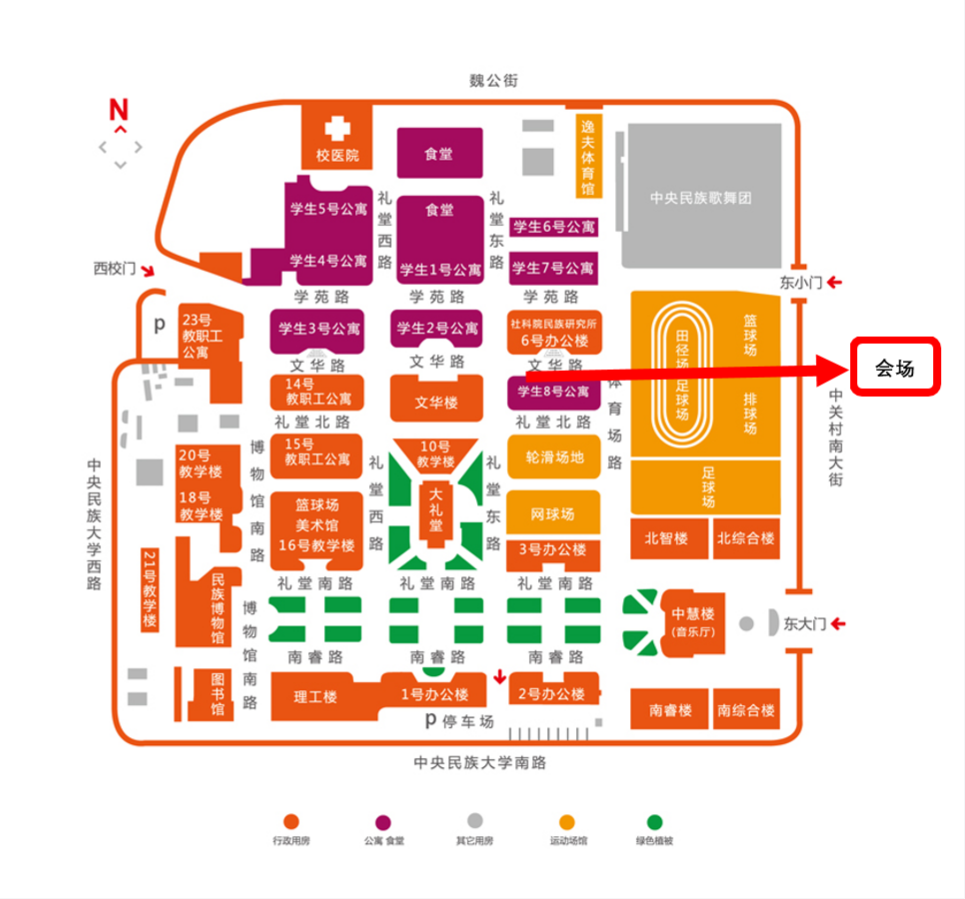
三、会议地点
1.线下会场:中央民族大学海淀校区知行堂
2.会议直播:https://meeting.tencent.com/l/ufQcQjXmualX
四、会议语言:中文
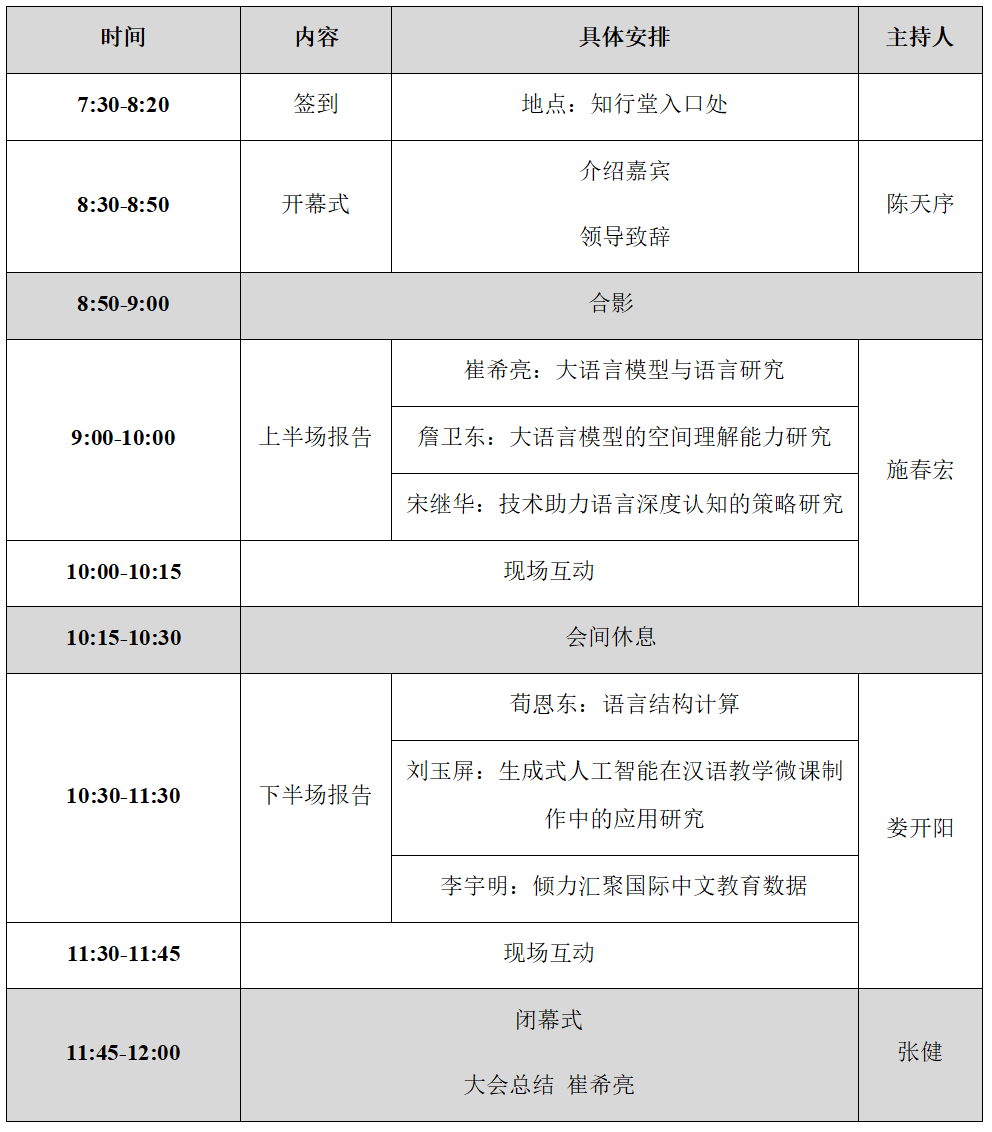
五、会议日程
时间:2024年12月8日(星期日)
地点:中央民族大学海淀校区知行堂
六、会议须知
本次年会免收会务费,食宿、交通费自理。线上参会代表无需报名,会议线上地址:https://meeting.tencent.com/l/ufQcQjXmualX
线下参会代表请您于12月4日前扫码填写参会回执。线下名额限80人,先到先得,收到确认邮件视为报名成功。

七、会务咨询
联系人:贺老师
会议邮箱:ht1617@muc.edu.cn
附件:报告嘉宾及报告内容(按主旨报告顺序)
(一)崔希亮(北京市语言学会理事长、北京语言大学教授)
报告内容:大语言模型与语言研究
【摘要】大语言模型尤其是生成性大语言模型(LLMs)的出现,对很多行业都产生了不可估量的影响,语言学界也开始反思语言学在人工智能背景下的研究范式。语言学家开始对大语言模型进行测试,从而生发出一些新的研究课题。日常生活中有很多语言问题,我们可以借助人工智能对这些问题进行多维度的研究。
(二)詹卫东(北京大学教授)
报告内容:大语言模型的空间理解能力研究
【摘要】近二十年来,深度学习技术显著提升了机器的自然语言处理能力,在诸多任务上接近甚至超过人类水平。尽管以ChatGPT为代表的大语言模型表现出类人的语言能力,但从大数据中学习到的语言符号分布模式是否能代表语言的全部意义,仍然存疑,特别是需要深层认知、结合语用情境才能准确理解的意义,机器的能力表现如何,还需深入研究。我们从2021年开始,连续组织了四届面向机器的空间理解能力评测大赛(从SpaCE2021到SpaCE2024)。本文将展开讨论评测中所用数据集的设计思想、数据集制作概况以及机器在空间语义理解任务上的表现特点。机器学习的对象不再是直接来自人类语言学研究成果(知识),而是人类语言材料(数据)。在AI高速发展使得语言学知识在计算机信息处理领域被动边缘化的当下,我们从研究空间理解能力评测任务数据集的工作中认识到,发挥语言学知识价值或许有新的途径,即从知识到数据,由语言学知识驱动来生产高质量高价值的语言数据。
(三)宋继华(北京师范大学教授)
报告内容:技术助力语言深度认知的策略研究
【摘要】全球教育数字化转型与《国际中文教师专业能力标准》、《教师数字素养》等标准的发布,对于国际中文教育领域人才培养、师生学术成长以及院校学科发展提出了更高要求,如何基于学理性与专业性兼具的已建数智化系统,来助力现有国际中文教育人才培养课程体系和培养模式的变革,使之不仅利于提升汉语言本体知识的深度认知,同时利于数智时代专业素养与数字素养的锤炼养成,进而有效解决时代发展亟需面对的主题和难题。本次交流拟从实例出发,释说针对性的问题解决之策。
(四)荀恩东(北京语言大学教授)
报告内容:语言结构计算
【摘要】结构角度,词、句子和篇章等不同自然语言对象,在形式、内容和功能等不同侧面,呈现不同的规律和特点。同时结构也是计算机程序设计语言(人工语言)核心内容。本报告重点论述从计算角度出发,结合语言学的组合性和聚合性,论述不同自然语言对象、不同侧面的语言结构的计算机表示,论述之间的关系。讨论显示和隐式两种样态的语言结构计算方法;讨论大语言模型解决场景任务时遇到挑战,本质是大语言模型无法高正确率地生成与应用任务对接的语用结构。
(五)刘玉屏(中央民族大学教授)
报告内容:生成式人工智能在汉语教学微课制作中的应用研究
【摘要】基于汉语教学微课的特点,运用生成式人工智能技术,设计制作汉语教学微课作品,采用专家评价方式考察生成式人工智能生成的微课的质量及教学可用性,对微课制作过程中的人机分工以及人机协作中的一些关键问题进行分析,总结生成式人工智能在汉语教学微课制作中的优势,思考国际中文教育数智化发展对教师素质的要求。
(六)李宇明(北京语言大学教授)
报告内容:倾力汇聚国际中文教育数据
【摘要】人工智能靠数据驱动,数据影响其发展水平与速度。国际中文教育既需要通用人工智能助力,更倚仗专用人工智能支持,而发展专用人工智能、打造 AI 助手,专业数据不可或缺。国际中文教育专业数据涵盖规划管理、教育教学、学习应用等诸多方面,要分类搜集。这类数据不止有文献、统计数据,动态数据也极为关键。相关人员与单位要有数据及数据资产意识,注重日常积累,还需组建专业团队,开展专项数据搜集、汇聚、加工、开发与交易工作。同时,数据生产初期就得做好授权、脱敏、规范事宜,借助数据市场交易产品,促进数据收集与应用。根据国家的数据政策和事业发展需求,及时制定国际中文教育专业数据的发展规划。规划应包括数据产品标准、数据资产评估、数据市场运作、数据产业伦理等,推进国际中文教育专业数据的发展进入企业化运作,保证国际中文教育专用人工智能研发的数据供给。
温馨提示
1.天气预报:
会议当天多云转晴,气温-1~4℃
建议穿棉衣、冬大衣、皮夹克、厚呢外套、呢帽、手套、羽绒服、皮袄等厚重保暖衣服。
2.交通信息:
地铁:乘地铁4号线或9号线至国家图书馆站步行至学校
公交:乘坐26路、86路、92路、305路、320路、332路、563路、609路、653路、658路、695路均可直接到学校